Historical simulation (HS) has been one of the most popular ways of measuring Value at Risk (VaR) in financial institutions. Originally popularized by JP Morgan’s RiskMetrics document and then picked up by the Basel Committee on Banking Supervision (BCBS), the idea is grounded in the belief that knowing history is a good starting point for understanding what lies head. In that view, a histogram estimated based on data over time can be used to calculate VaR for tomorrow or the day after. Of course, put this way, the approach does not seem very satisfactory. Knowing what all has happened over time is not quite the same as knowing what all can happen at a point in time in the future, but like it or not, that’s how such methods roll. Those who like HS argue that at least it is better than assuming a Normal distribution.
Anyways, that’s not the issue practitioners had with using HS. What they didn’t like was the in-built notion in HS that all history was equally important. So if you asked from HS what would be the 5% VaR on the HDFC stock tomorrow, it would say, well, just order the returns in the ascending order and pick the 5th percentile. Or maybe, what is more visually appealing, just pick it off its histogram. And it is a rather good idea. In fact, that is the sort of thing one usually does if one had to, say, find the height of the 5th shortest kid out of the 100 in one’s housing society.
While this approach works for finding the kid with the 5th shortest height kid, it doesn’t quite work so well for finding the 5% VaR. What’s the problem you say? Like with many other things in finance, it has to do with time and memory. When the only data you have is from the past, some of that could be from a very very long time ago. And as times change, so do the rules of the game and technology and what not. So the importance of value of a stock return calculated in early 2010s is not quite the same as a return calculated yesterday. After all, if the objective is to find the risk in holding the HDFC stock over the next day or week, surely what happened last week or last quarter carries more importance than what took place 10 years ago.
Another problem is that relying only on past data to form opinions about the future assumes that financial markets have no memory, that is, it is as if all returns are completely independent. Often when financial markets go crazy or get hit by once in a generation virus, volatility stays high and stocks fall for days at a stretch. Unfortunately, the fact this happens sort of throws many assumptions underlying HS out of the park.
That the recent past should be more important and that memory matters for measuring future risks, of course, everybody knows that. And to be fair it’s not that finance folks didn’t realize these things. But VaR itself only took off around the early 1990s, and it wasn’t taken all that seriously back then. I mean, statisticians and risk managers were hardly in demand in the early 1990s – well, not like now in any case. Anyways, over time, folks who were interested in HS took these problems seriously, and figured they had to fix it. And different people came up different ways to address the issue.
Weighted historical simulation
The attempts at modifying HS so that it relied more on recent data broadly came in three avatars:
- Use a window of only very recent data: Obvious and easy-peasy but then two things happen: i) the sample size goes down, and ii) if something relevant, like a big systemic crisis, did happen some time ago it would go missing from your history pretty soon (as time passes that event would no longer part of the recent window).
- Weight data by age: This again is sort of obvious. I mean if you’d rather that more weight be given to recent data, well, just do that. Boudoukh, Richardson and Whitelaw were one of the first set of guys to flesh out this idea and showed how to apply it in practice in an article in Risk magazine in 1998. They said, let’s decide on some number
 between 0 and 1, perhaps close to 1, and multiply historical observations with powers of. So, yesterday’s return could be multiplied by and the one before by
between 0 and 1, perhaps close to 1, and multiply historical observations with powers of. So, yesterday’s return could be multiplied by and the one before by  and so on. That was the basic idea and so now you could use all historical data, and if something happened long ago it wouldn’t matter much anymore, unless the things that happened were like really major. One needs to do a bit more work to identify the VaR, but the idea is intuitive.
and so on. That was the basic idea and so now you could use all historical data, and if something happened long ago it wouldn’t matter much anymore, unless the things that happened were like really major. One needs to do a bit more work to identify the VaR, but the idea is intuitive.
- Weight data by volatility: Around the same time when Boudoukh and others were thinking about modifying HS by using weights, some folks got the idea to think about weights a bit differently. They said, look, returns are already scaled so it shouldn’t matter that much which epoch they are from as long as they are not from an era super old, but the memory effect needs to be taken more seriously. If the whole method of HS goes for a sixer if returns over days are not independent then that’s really bad news. Since this was an important development historically, this probably deserves a separate section to talk about it.
Volatility weighted historical simulation
As it often goes with such things, the idea of applying volatility weights also came up around the same time. In 1998, Hull and White noticed that if they divided past returns with the volatility at that time, the memory effect disappeared to a large extent. So with volatility weighted data, HS could be salvaged and applied sensibly. But that’s awkward now, isn’t it? They got rid of the memory effect, but that meant taking away the affect of probably the most important input for measuring risk, that is volatility. To bring volatility back, they came up with a hack.
They argued that, look, the objective is to find VaR over the next few days so then what better volatility to use then the most recent one available. And the fact that volatility is persistent is great for us, meaning one could use today’s volatility and it would still be a very good proxy for volatility tomorrow. One needs to figure out how to measure volatility properly, but that’s hardly a bottleneck. Thanks to Robert Engle and friends, we have had that technology since the 1980s. For the task at hand one could use any of the many time series based models of volatility, EWMA, GARCH, EGARCH, you name it. In fact, it turns out that the choice of the volatility model does not even matter that much as long as it’s kind of reasonable.
If 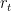 is the series of historical returns, Hull-White suggested applying HS to volatility weighted returns series as:
is the series of historical returns, Hull-White suggested applying HS to volatility weighted returns series as: 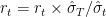 , where
, where 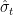 is the estimated volatility at time
is the estimated volatility at time  from, say, a GARCH model and
from, say, a GARCH model and  is the today’s (latest) estimate of volatility. So implementing volatility weighted HS (WHS) VaR requires two additional steps: i) dividing the returns by estimated volatility, and ii) multiplying by the latest estimate of volatility.
is the today’s (latest) estimate of volatility. So implementing volatility weighted HS (WHS) VaR requires two additional steps: i) dividing the returns by estimated volatility, and ii) multiplying by the latest estimate of volatility.
Taking an example for the HDFC stock (sample period 2006 – 2019), as of December 31, 2019, 1-day HS VaR at 5% is -3.14%, and corresponding WHS VaR estimates using EWMA and GARCH are -1.85% and -2.01% respectively. So which one is the best/most reliable? Well, that’s where the things get a bit tricky. Going by the numbers for the HDFC example (and this is sort of the case in general), there is no secular trend, so we can’t say for sure if HS VaR is always less/more than the WHS VaR (for now ignoring the matter of point estimates versus confidence intervals). Unfortunately, that’s how often such things are. For now, we will not get into this and move on and try to see where does filtered historical simulation fits into all of this.
Filtered historical simulation
Despite the attractiveness of WHS over HS in i) sampling from approximately uncorrelated data, and ii) giving more emphasis to the current volatility, practitioners still found it lacking in two ways. One, there was no systematic way of forecasting VaR beyond a day (short of assuming square root scaling which is strictly only applicable for IID Normal variates) and two, it wasn’t obvious how to extend the idea to portfolios or derivatives.
The variant of WHS that claims to do both, and which has become particularly popular in the last few years, is called filtered historical simulation (FHS). Introduced by Giovanni Barone-Adesi in a series of papers around 1999, FHS applies volatility weighting in exactly the same way as EWMA/GARCH WHS does (FHS calls the rescaling step as ‘filtering’), but it goes a step further and casts the exercise within an ARMA/GARCH framework. This allows for forecasting returns as well as volatility, and consequently VaR, within a formal time series model which is sort of internally consistent.
The second modification in FHS is its adapting Bradley Efron’s idea (see chs. 7 to 9) of applying bootstrap on a strip of contemporaneous data to simulate a vector of returns. The two are combined to simulate the distribution of filtered returns at any point in the future. Applying the idea to the HDFC stock, 1-day 5% FHS VaR using EWMA and GARCH come out to be -1.79% and -2.07% respectively.
That the FHS and WHS estimates are so close is not altogether unexpected. The only differences between WHS and FHS are really the use of bootstrap to find the quantile and forecasting volatility for 1 day ahead in the latter, both of which do not amount to much for finding 1 day VaR. The claimed attractiveness of FHS over WHS lies in i) its ability to forecast VaR beyond a day, and ii) finding VaR for portfolios and derivatives without relying on correlations.
One of the practical difficulties in forecasting VaR for portfolios and derivatives has been instability/unavailability of correlations. The only model free method really available for linear portfolios was HS, which one could use to find VaR based on historical portfolio returns. Other parametric methods all require correlations. There is unfortunately no easy way to apply WHS either, short of using a complicated and unstable multivariate GARCH models which again depend on correlations.
The fact that FHS applies bootstrap on filtered data provides a way out. FHS uses sampling with replacement on standardized residuals to create a distribution of returns. It turns out that this idea can be extended to portfolios as long as we can sample strips of standardized residuals for different assets at the same time. This seems like a neat hack, as prima facie one would expect sampling residuals for assets together would respect dependence between standardized residuals.
The rest of the algorithm for forecasting remains the same as described above. Having obtained the path of returns and volatility, the portfolio VaR can then be calculated in the usual way. Once joint returns are simulated, they can be used to create joint price paths for valuing derivatives.
FHS with AR(1)/GARCH(1, 1) (wonkish)
To illustrate how FHS is implemented, let’s assume that an AR(1)/GARCH(1, 1) model has already been fitted to the returns series 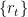 .
.

The distribution for  is generated by applying bootstrap on estimated standardized residuals
is generated by applying bootstrap on estimated standardized residuals  . Denoting the first such bootstrapped sample by
. Denoting the first such bootstrapped sample by 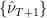 , the next step is multiplying bootstrapped with the forecast of
, the next step is multiplying bootstrapped with the forecast of  , as:
, as:

The algorithm for generating a distribution for  and beyond proceeds similarly, except that now there are as many possible values for
and beyond proceeds similarly, except that now there are as many possible values for 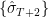 as bootstrapped
as bootstrapped  .
.

In terms of multiplication of arrays, the product  is to interpreted in the sense of element-wise multiplication (
is to interpreted in the sense of element-wise multiplication (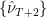 represents a separate bootstrap from ). Once
represents a separate bootstrap from ). Once 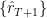 and
and 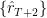 are generated, VaR at
are generated, VaR at  at any percentile, say, 5% can be picked off as the 5% percentile of .
at any percentile, say, 5% can be picked off as the 5% percentile of .
Assuming that returns data is stored in the first column of an R dataframe/xts obect called returns, the following implements a 1-day 5% HS, WHS and FHS VaR estimates using ARMA(0, 0)/GARCH(1, 1) model (using the rugarch package).
hs <- quantile(returns[, 1], 0.05)[[1]]
specGarch <- ugarchspec(mean.model=list(armaOrder=c(0,0), include.mean=FALSE)),
distribution = 'std')
fitGarch <- ugarchfit(specGarch, returns[, 1], rec.init = 'all')
returns$volGarch <- sigma(fitGarch)
returns$scaledGarch <- returns[, 1]/returns$volGarch
whsGarch <- quantile(returns$scaledGarch, 0.05)[[1]] *
as.numeric(tail(returns$volGarch, 1))
bootGarch <- sample(returns$scaledGarch, num, replace = TRUE)
fhsGarch <- quantile(bootGarch, 0.05)[[1]] *
as.numeric(sigma(ugarchforecast(fitGarch, n.ahead = 1)))
